
How to Improve Debugging Skills?
5 steps to root cause issues like a pro!

Have you ever been stuck trying to debug an issue that seemed impossible to root cause? It can be frustrating and scary. Most engineers panic. Great engineers debug. Those “great” engineers may seem to have a lot of context, but in reality, they have invested in core debugging skills and practiced them. They just got great over time.
As a Staff Engineer, I have often helped my teammates when they encounter impossible-to-root-cause issues. In doing so, I’ve observed common roadblocks that often trip engineers up. Whether it’s getting lost in a sea of logs, misinterpreting error messages, or simply not knowing where to start, many engineers find themselves stuck in a loop of frustration. What separates those who struggle from those who succeed is not always context or experience but the debugging mindset and process they employ.
Today, I will share my high-level steps so that you can skyrocket your debugging skills.
WorkOS: Start selling to enterprises with a few lines of code (Sponsor)

WorkOS is a modern identity platform for B2B SaaS. It provides flexible and easy-to-use APIs to ship user management, SSO, SCIM provisioning, and fine-grained authorization in minutes instead of months.
WorkOS powers some of the world's hottest startups, including Perplexity, Vercel, and Webflow.
💪 Step 1 - Don’t give up!
Believe in yourself, and don't give up on investigations without trying. Many people think they are not experts and hold back, but it's important to be curious.
However, remember not to be over-confident. You should understand where your knowledge is lacking and be open to seeking help.
📚 Step 2 - Learn the basics
If your foundation is weak, being productive in your debugging sessions will be hard.
You should invest in the following upfront:
Know where to find the logs, process cores, alarms, metrics, dashboards, runbooks, etc.
Have a reasonable grasp of how various components interact with each other.
Know how to search the codebase - not just your team's but also your dependencies.
Remember, it's okay if you don't know everything.
✅ Step 3 - Validate your understanding
You can’t make progress if you don’t understand what the bug is. Sometimes, people don’t realize they are stuck. They cannot articulate the problem to themselves and look at too many logs/charts in a haphazard order. The best way to get unstuck is to explain the problem to a four-year-old (metaphorically, of course).
Here is what works for me with an example situation (Imagine there is an active Service Overload alert)
What is a brief description of the problem?
"The alert for service overload fired for all of production or scoped to X regions."
Look for metrics that prove the problem. Even better, use the timeline view to understand when the issue started.
Look at the single "overload" metric that is over the threshold.
Maybe you will find out that it started happening at 10 am today.
How is the "overload" metric calculated? Is it a derivation of different resources or something artificial?
Do the metrics show more sub-problems?
Are the requests failing due to server overload? If so, by how much?
Are the requests taking longer to complete?
Are there more requests coming into the service?
Which customers are impacted? If so, how badly?
Ensure you are not distracted by unimportant and unrelated problems.
Don't focus too much on the outliers. For example, some requests likely took longer, even before the overload occurred. They may not be interesting to look at.
Don't focus on customers who are sending a handful of trivial requests.
Filtering noise can be hard for someone inexperienced. So, rely on your runbooks or previous investigations.
So, my point is to be curious and ask “why” at every step. When you try to understand beyond just the surface-level concepts, you will get closer to the root cause.
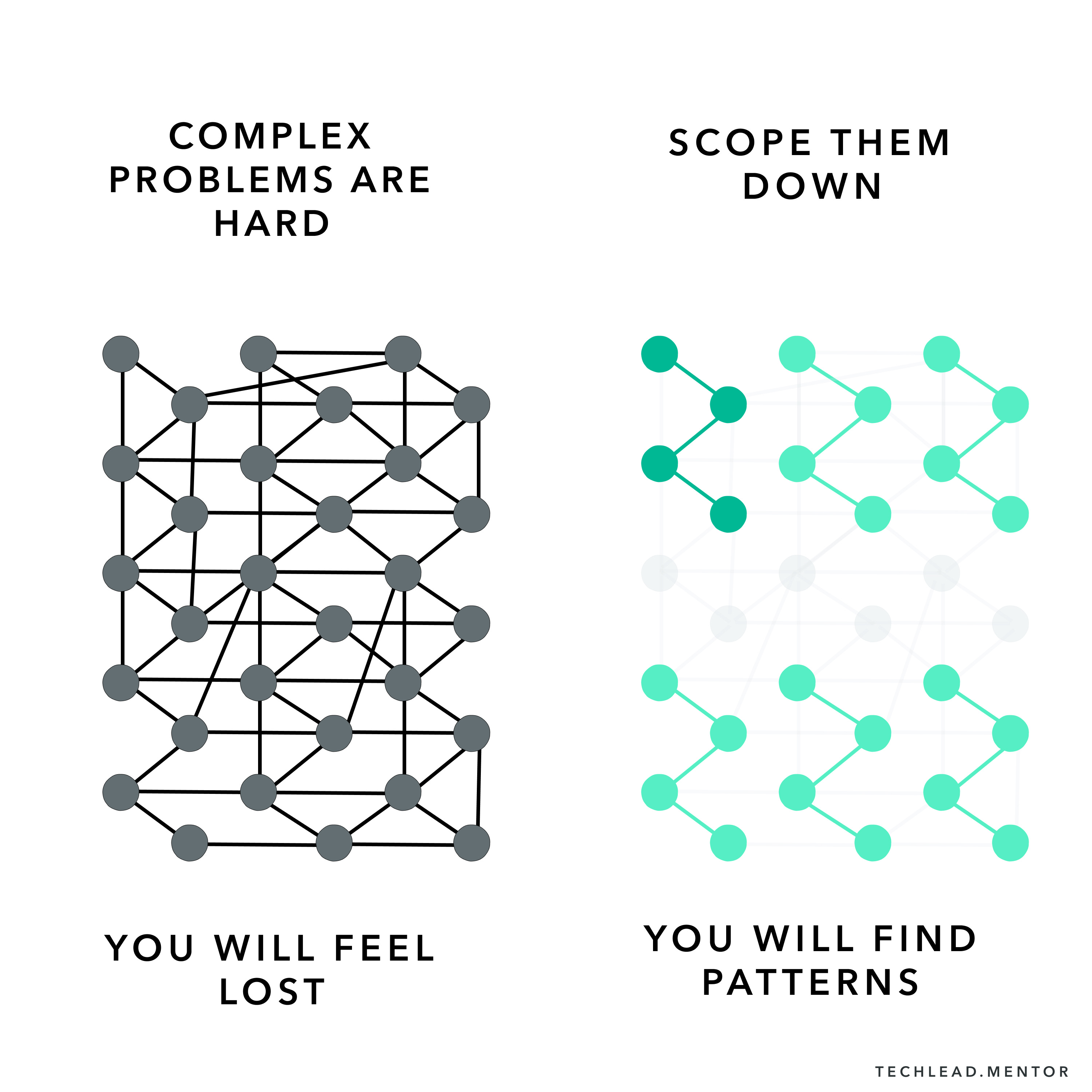
🔍 Step 4 - Scope down the problem
It is easier to go in circles when you only look at macro metrics. To get to the root cause, you need to narrow it down to something scoped and smaller.
Using the same example of service overload:
Can you find a single instance?
Is a specific kind of request taking longer?
Is a downstream dependency taking longer?
Can you enable high-fidelity logging to find out more about this single instance?
If the number of requests increased, can you narrow down which customer sent them?
Did other things happen around that time?
Was there a config change? New code deployment?
Has your rate limiting or autoscaling stopped working?
Can you issue dummy requests to see if that reproduces the problem?
Don't get stuck trying to tackle the behemoth. Instead, break down the problem into smaller, manageable issues.
🤝 Step 5 - Ask for help
So, you have validated the problem to a certain extent and have scoped it down. But you are unable to make further progress. That is fine, and naturally, you should ask for help.
One of the hardest things to do is ask for help the "right" way during an intense situation. Try these:
Give a brief description of the problem with supported metrics.
Articulate your understanding of the situation and your working hypothesis.
Explain why you believe your hypothesis is likely true. Provide supporting metrics and logs.
Clearly state what you do not know and the gaps in proving your hypothesis.
Many engineers can explain what they understand but struggle to identify what they don't understand.
Your peers should not have to play a guessing game while trying to help you.
For example, others can provide concrete guidance when you say that you don't know how to find downstream latencies or are unaware of all downstream dependencies.
Don't share information piece by piece.
Provide a bird's eye view of the problem while asking for specific things.
The worst thing you can do is ask overly specific questions that help you prove your hypothesis. Your peers may not have the context and cannot correct you if your original hypothesis is wrong. This will lead you in the wrong direction.
Treat your peers as a brainstorming resource rather than a Q&A bot.


🔄 Continuous improvement
Don’t expect to be great at debugging during your first major issue. One of the best ways is to learn from what you missed this time:
When you seek help, don’t just seek the answer. Understand how your peers got to the answer.
Make a note of the shortcuts others took or the context you didn’t have
If the quality of the logs is poor, then improve it for the next time.
These steps serve only as a template and must be converted into actionable items that apply to your software and problem. You also need to practice them a few times to see results. Lastly, debugging is a great strength for any engineer who wants to rapidly grow in their career. So invest in this essential skill today.
If you enjoyed this article, then hit the ❤️ button. It helps!
If you think someone else will benefit from this, then make sure to 🔁 share this post.
I'd add one more: Go out and take a walk, sometimes the best way to solve a problem is to letting your mind to rest, after that we can see the problem with a different perspective and realized about something we did not notice before